简易Node后端搭建
1. Express
1.1 安装
1.1.1 安装淘宝镜像
安装npm之前可先安装淘宝镜像,使用cnpm的来代替npm,使得下载速度提高很多。
1 | npm install -g cnpm --registry=https://registry.npm.taobao.org |
1.1.2 初始化项目
目录下运行命令来初始化项目,期间所有提示按enter键即可,这会生成package.json,用于描述项目文件的.
1 | cnpm init |
再输入命令,项目目录中又会多出一个叫node_modules文件夹,里面是node.js提供的模块
1 | cnpm install |
1.1.3 安装express
1 | cnpm install express --save |
创建结果:

1.1.4 检验是否创建成功
1 | express --version |
若出现版本号,则为创建成功
1.2 Express脚手架的安装
1.2.1 使用express-generator安装
命令行进入项目目录,运行命令
1cnpm i express-generator创建了一个名为app的Express应用,并使用ejs模板引擎
1express --view=ejs app进入app,并安装依赖
1cd app初始化项目
1npm install在Windows下,使用以下命令启Express应用
1set DEBUG=app:* & npm start
1.2.2 使用express命令快速创建项目目录
用法:express项目文件夹的名字 -e
1 | express app -e |
2 | cd app |
3 | cnpm install |
app文件夹下的文件结构:
- bin: 启动目录,包含启动文件www,默认监听端口是 3000 ,直接node www执行即可。
- node_modules:依赖的模块包
- public:存放静态资源
- routes:路由操作
- views:存放ejs模板引擎
- app.js:主文件
- package.json:项目描述文件
1.3 参考资料
Express全系列教程之(一):Express的安装 和第一个程序
2. sequelize
2.1 安装
2.1.1 安装sequelize
1 | cnpm install sequelize -S |
2.1.2 为MySQL数据库安装驱动程序
1 | cnpm install mysql2 -S |
2.1.3 安装
通过命令行创建sequelize目录
1 | cnpm install sequelize-cli -g |
1.1.4 初始化项目
1 | sequelize init |
文件目录:
- config – 数据库配置
- migrations – 迁移文件
- models – 模型文件
- seeders – 种子文件
2.2 配置数据库环境
2.2.1 环境参数
2.2.2 配置参数
1 | "development": { |
2 | "username": "root", |
3 | "password": "root", |
4 | "database": "document_development", |
5 | "host": "127.0.0.1", |
6 | "dialect": "mysql" |
7 | }, |
2.3 创建数据库
1 | sequelize db:create --charset 'utf8mb4' |
创建成功:
2.4 sequelize操作数据库:模型、迁移与种子
2.4.1 创建模型与迁移
1 | sequelize model:generate --name Article --attributes title:string,content:text |
创建了名为Article的模型 ,表有两个字段:标题(string类型);内容(text 类型)
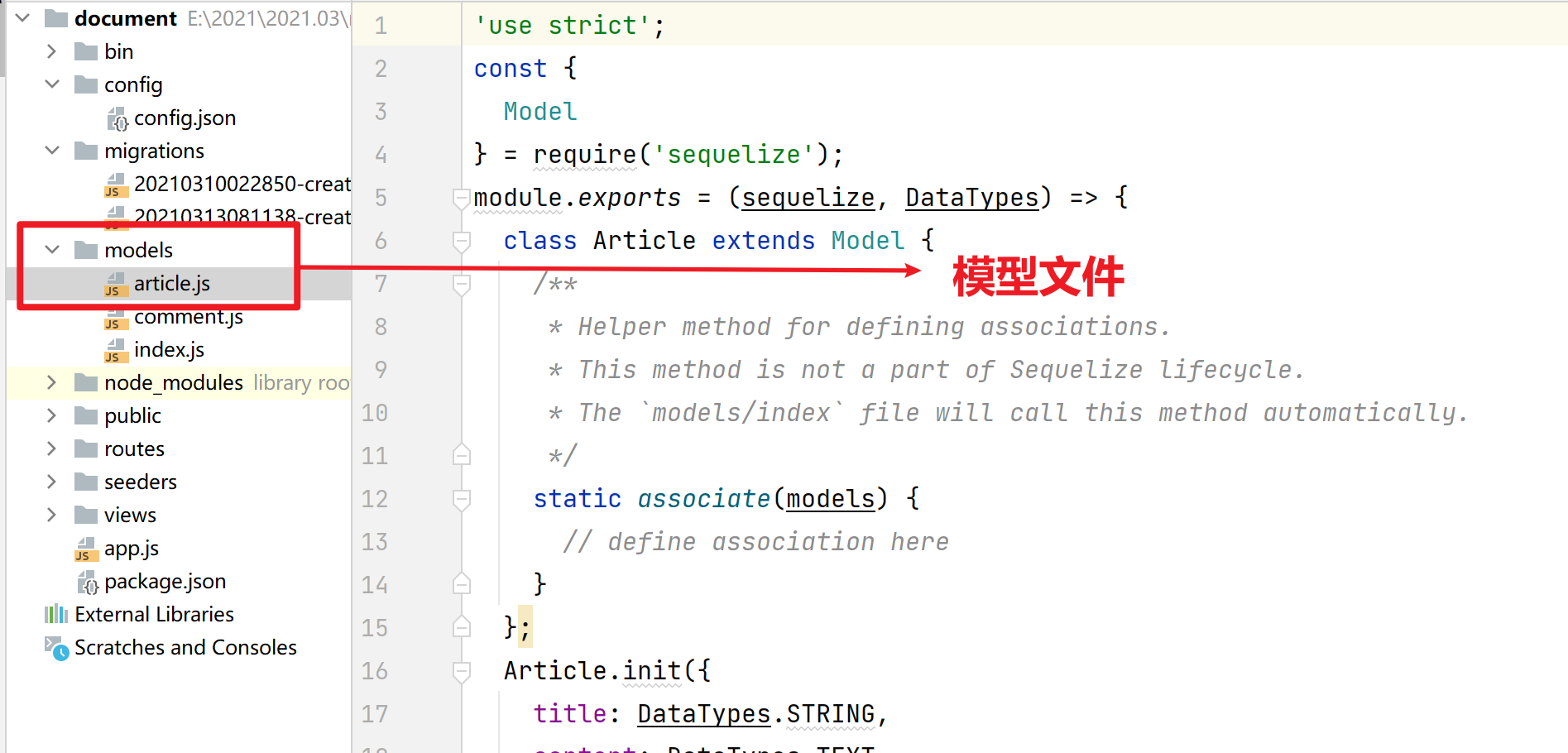
2.4.2 模型文件
使用 Node.js 操作数据库需要用到模型文件,无需改动。
2.4.3 迁移文件
迁移文件:migrations/xxx-create-article.js,里面保存的是 Articles 的字段。
(注意:sequelize 中默认规定,模型的名称是单数,而数据表是复数)

up部分代码 – 建表:

down部分代码 – 删除表:
代码的 down 部分,是 up 的反向操作。

2.4.4 运行迁移
1 | $ sequelize db:migrate |
运行命令,将字段迁移进数据库
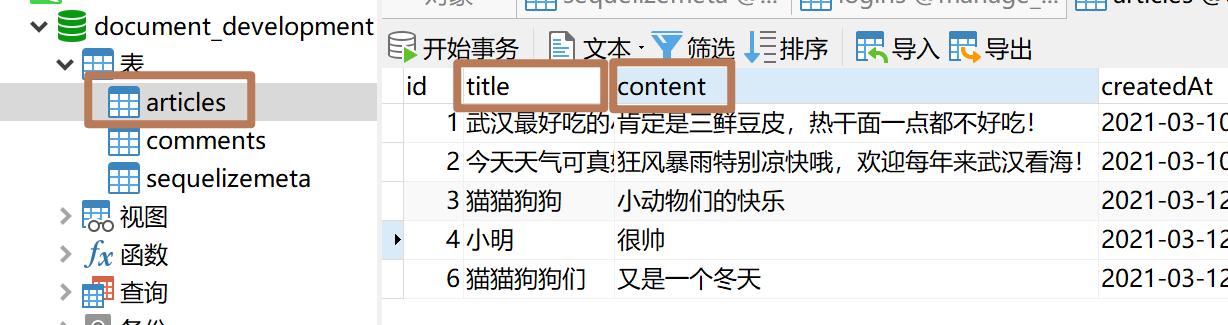
2.4.5 种子文件
创建种子文件,填充测试数据:
1 | $ sequelize seed:generate --name article |
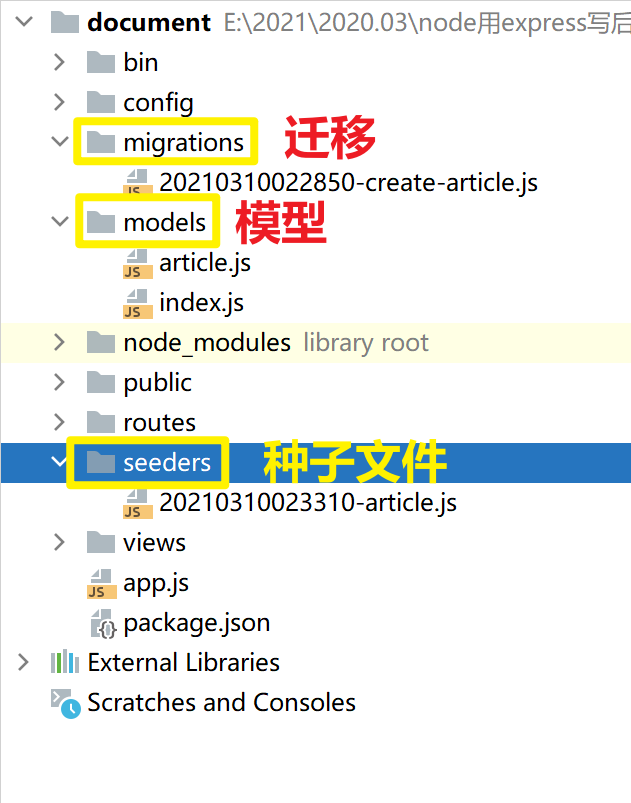
修改种子文件数据

运行种子文件
- 运行所有种子文件:
1 | $ sequelize db:seed:all |
- 运行指定的种子文件
1 | sequelize db:seed --seed xxx-article |
2.4.6 总结
日常开发项目数据库操作的步骤:
| 步骤 | 命令 | 说明 |
|---|---|---|
| 第一步 | sequelize model:generate –name Article –attributes … | 建模型和迁移文件 |
| 第二步 | 人工处理 | 根据需求调整模型和迁移文件 |
| 第三步 | sequelize db:migrate | 运行迁移,生成数据表 |
| 第四步 | sequelize seed:generate –name article | 新建种子文件 |
| 第五步 | 人工处理 | 将种子文件修改为自己想填充的数据 |
| 第六步 | sequelize db:seed:all | 运行种子文件,将默认数据填充到数据表中 |
2.5 查询数据库
2.5.1 路由
添加一个新的路由文件:在 routes 中,添加一个叫做 articles.js 的文件。基础的代码,和项目自带的其他路由文件一样,直接复制过来。

1 | var express = require('express'); |
2 | var router = express.Router(); |
3 | // .... |
4 | module.exports = router; |
2.5.2 get 请求
1 | router.get('/', function (req, res, next) { |
2 | res.json({hello: "ITFun"}); |
3 | }); |
代码解析:

2.5.3 使用路由
app.js 中使用articles.js 路由,路由文件才会生效
1 | var articlesRouter = require('./routes/articles'); |
2 | // ... |
3 | app.use('/articles', articlesRouter); |
2.5.4 读取数据库
1 | var models = require('../models'); |
2 | // ..... |
3 | router.get('/', function (req, res, next) { |
4 | models.Article.findAll().then(articles => { |
5 | res.json({articles: articles}); |
6 | }) |
7 | }); |
结果:

2.5.5 异步查询语法
1 | router.get('/', async function (req, res, next) { |
2 | var articles = await models.Article.findAll(); |
3 | res.json({articles: articles}); |
4 | }); |
async是异步的意思,async function表明当前这个function是异步的。await,表示等待一个异步方法执行完成。await只能在async函数内部使用,用在普通函数里就会报错。
2.5.6 排序
1 | var articles = await models.Article.findAll({ |
2 | order: [['id', 'DESC']], |
3 | }); |
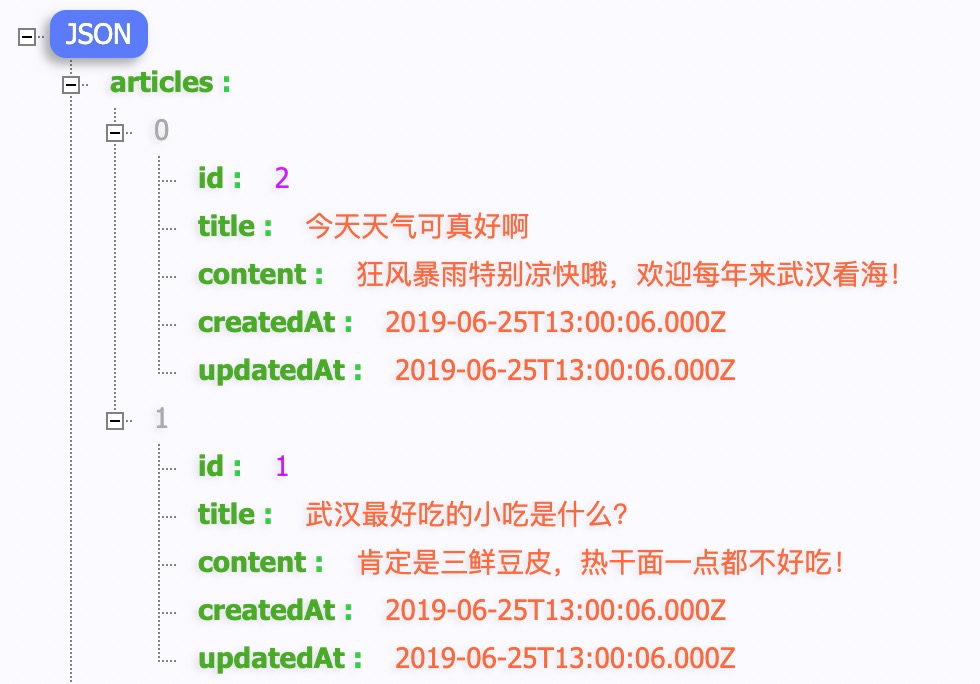
2.6 添加数据
2.6.1 新增定义死的数据
找到模型后,使用 create 方法,将数据插入进去
1 | router.post('/', async function (req, res, next) { |
2 | var article = await models.Article.create({ |
3 | title: "猫猫狗狗", |
4 | content: "小动物们的快乐" |
5 | }) |
6 | |
7 | res.json({article: article}); |
8 | }); |
2.6.2 使用Promise 语法
1 | models.Article.create({ |
2 | title: "asdf", |
3 | content: "asdfsadfsdf" |
4 | }).then(article => { |
5 | res.json({article: article}); |
6 | }) |
2.6.3 使用Postman测试接口
请求方式改为 POST,地址栏填上接口的地址。最后点击 Send
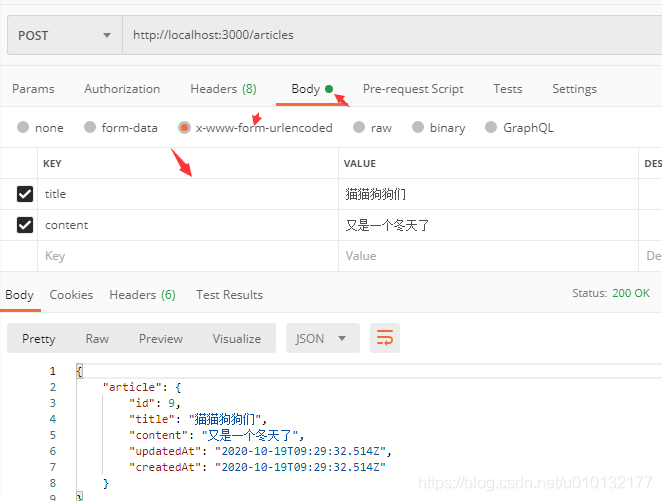
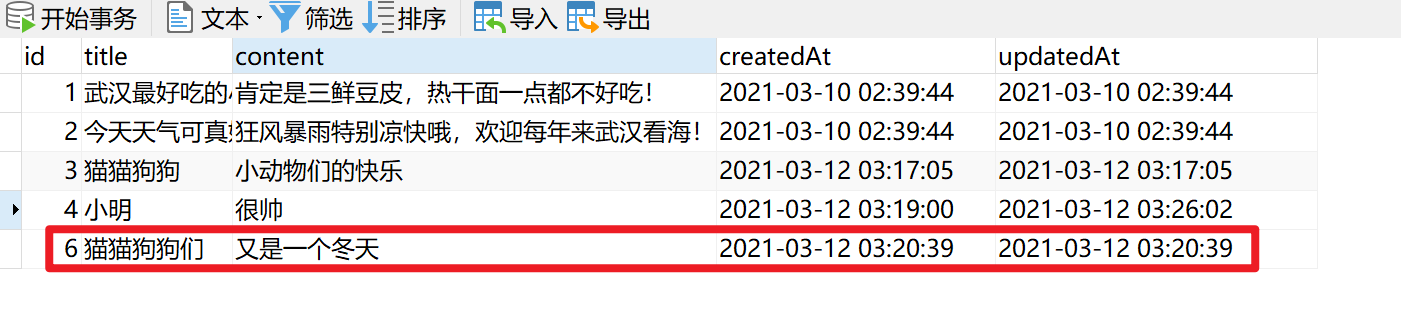
2.6.4 用户提交数据
1 | router.post('/', async function (req, res, next) { |
2 | res.json({'你发送的内容是': req.body}); |
3 | }); |
注:req.body:用户使用 post 发送过来的内容
测试接口
打开 Postman,点击 Body,选择 x-www-form-urlencoded。key 要填对应数据库里的字段名称,value 里填插入数据库的数据。
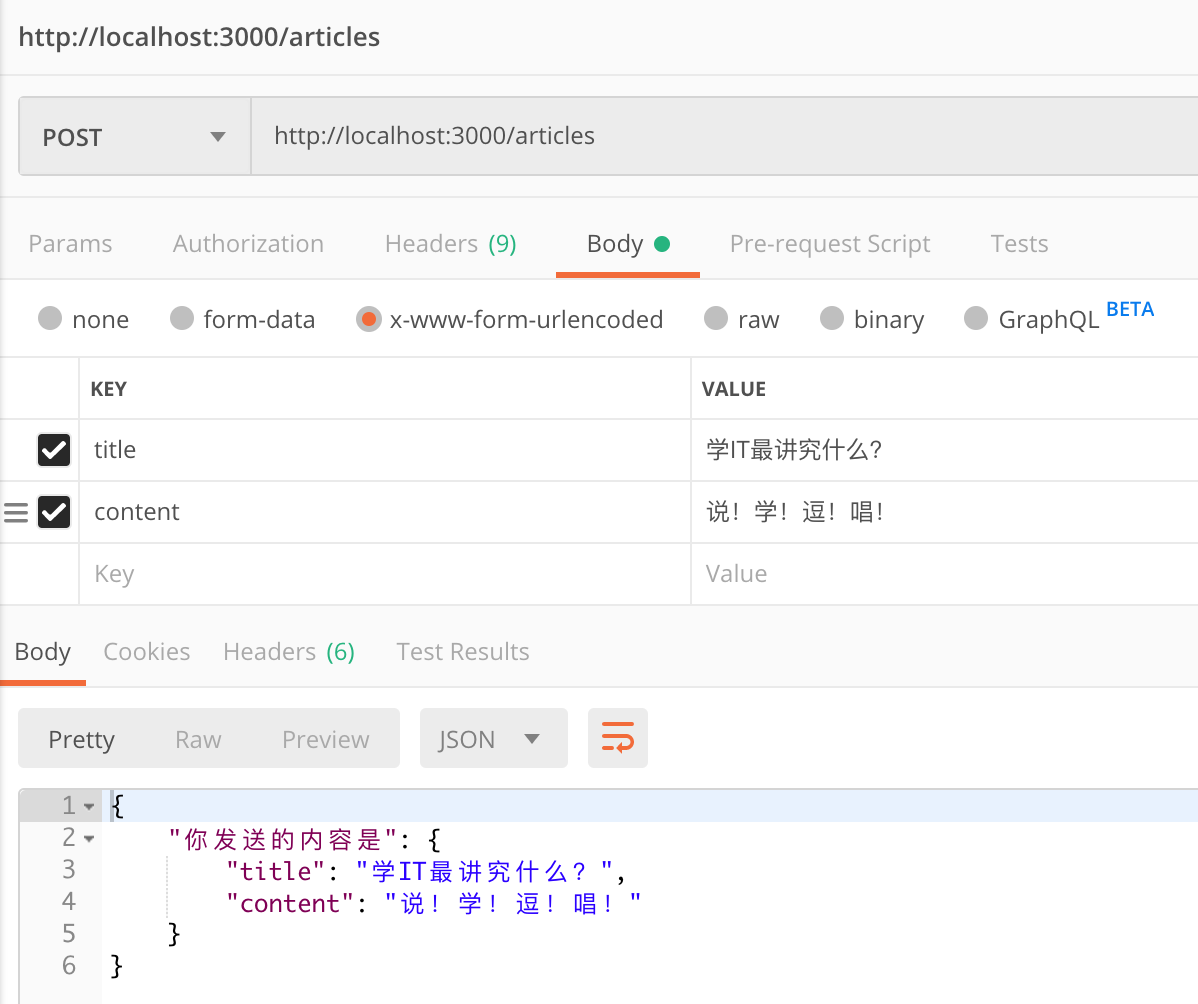
2.6.5 将用户的数据插入数据库
1 | router.post('/', async function (req, res, next) { |
2 | var article = await models.Article.create(req.body); |
3 | res.json({article: article}); |
4 | }); |
2.7 数据库的删改查
2.7.1 id属性
将id作为查询依据:
- 每个数据都有
id属性 id属性自增,永远不会重复的

定义的路由的时候,就在 / 后面加上一个 :id。这样定义后,表示这里可以接受一个 文章id 参数。
1 | router.get('/:id', async function (req, res, next) { |
2 | res.json({id: req.params.id}); |
3 | }); |
使用 req.params.id方法,可以取到传入的id值
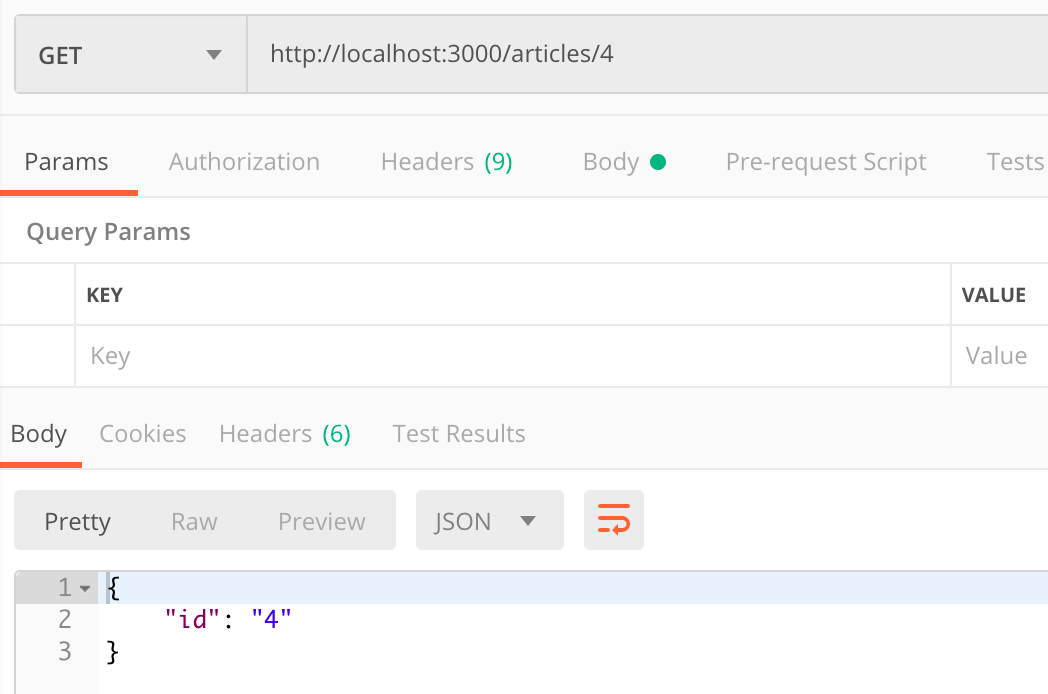
2.7.2 查询
接收到用户传递的id值后,在模型中调用findByPk。 就可以在Articles表中找到当前文章
1 | router.get('/:id', async function (req, res, next) { |
2 | var article = await models.Article.findByPk(req.params.id); |
3 | res.json({article: article}); |
4 | }); |
注意:
findByPk,这里的Pk是Primary Key也就是主键的缩写。一般每个表都有个主键,如果没有特殊命名,一般来说就是id字段
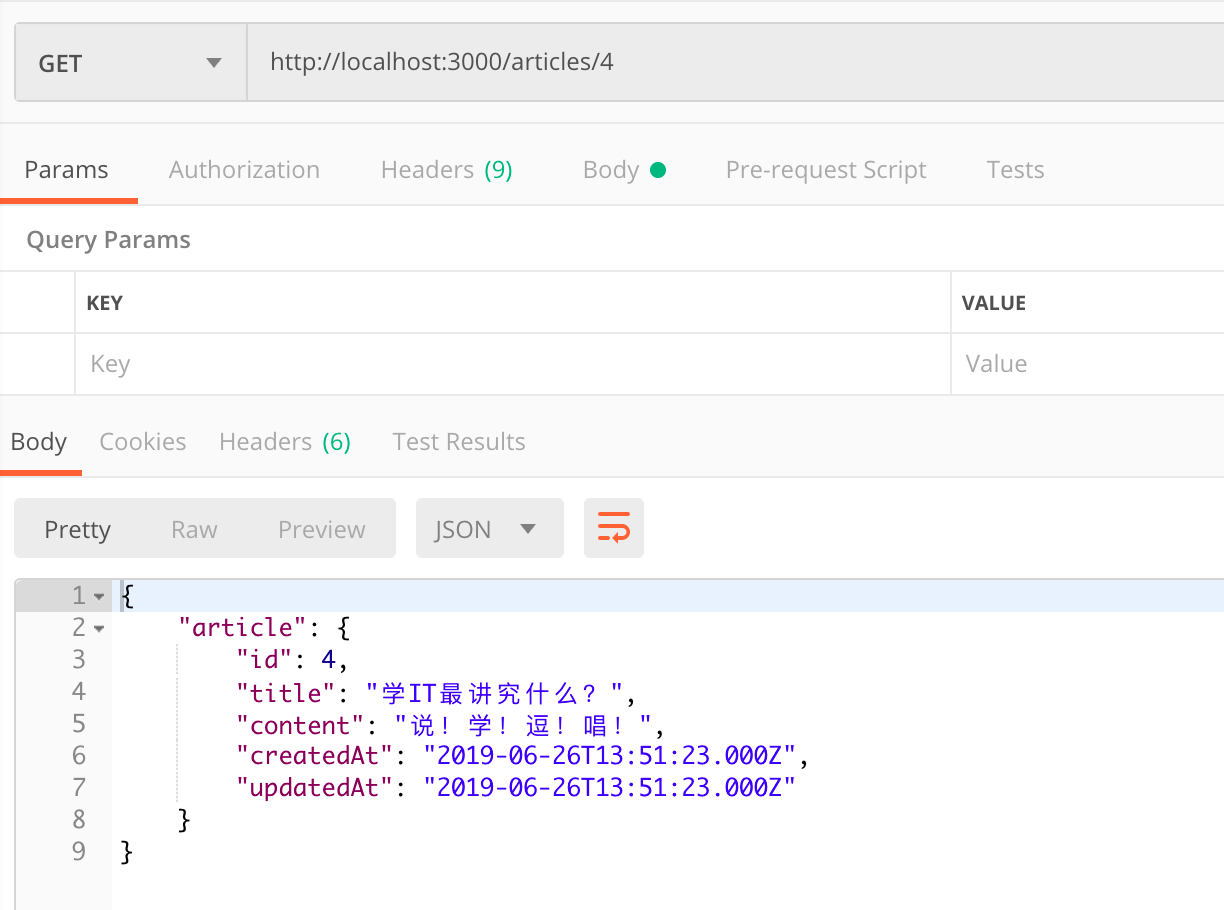
2.7.3 修改
1 | router.put('/:id', async function (req, res, next) { |
2 | var article = await models.Article.findByPk(req.params.id); |
3 | article.update(req.body); |
4 | res.json({article: article}); |
5 | }); |
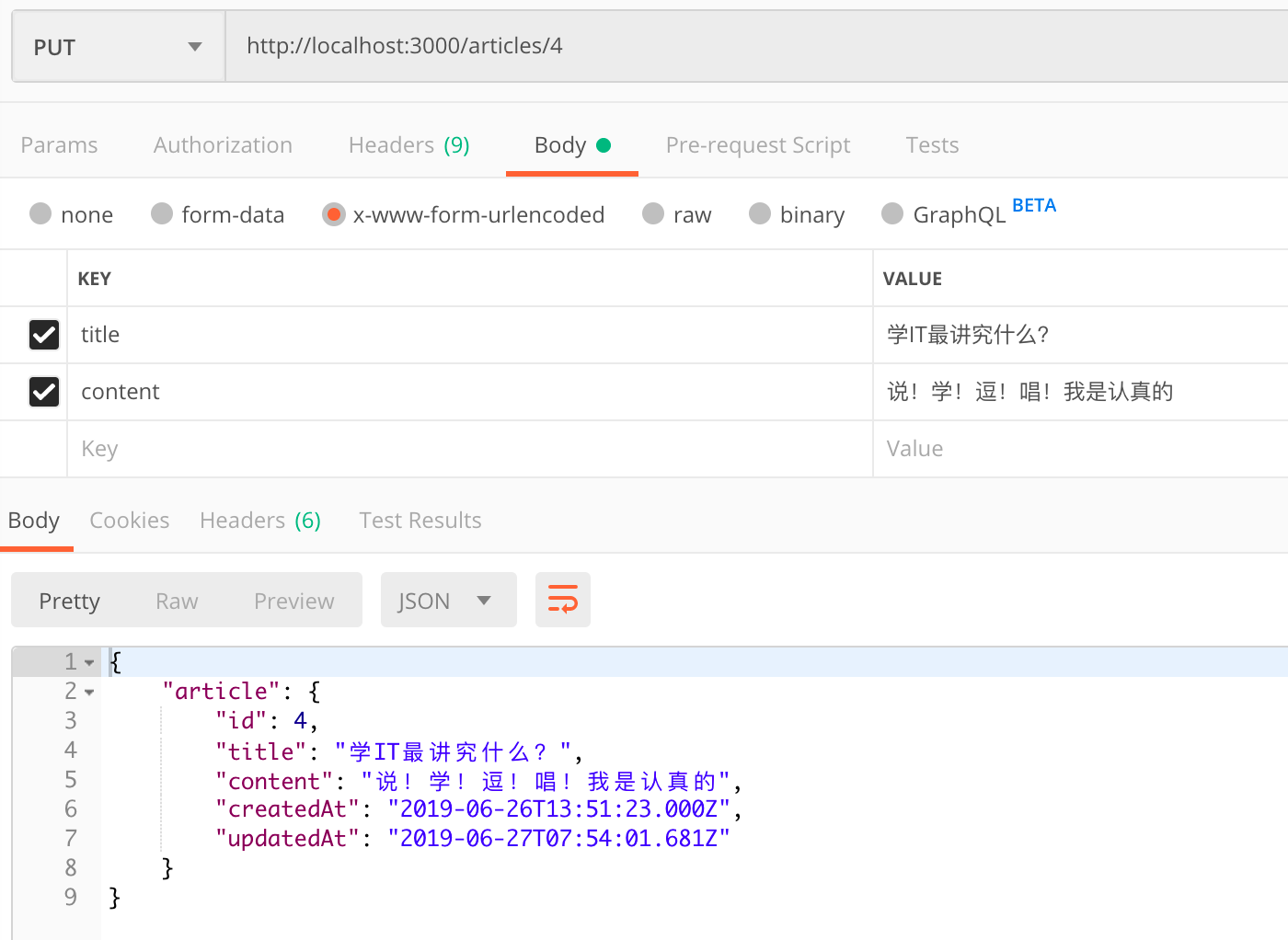
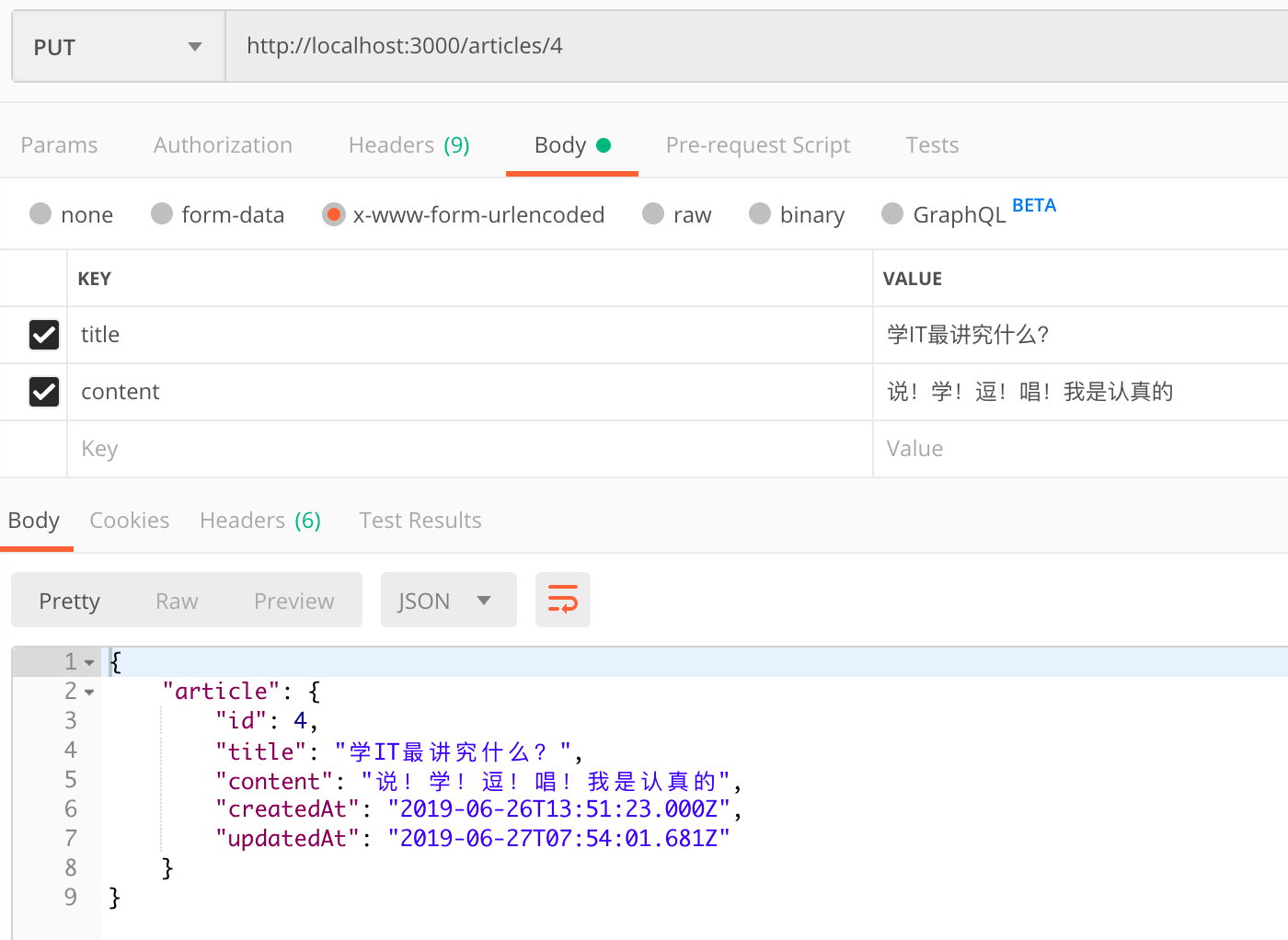
2.7.4 删除
1 | router.delete('/:id', async function (req, res, next) { |
2 | var article = await models.Article.findByPk(req.params.id); |
3 | article.destroy(); |
4 | res.json({msg: '删除成功'}); |
5 | }); |
使用的请求方式是 delete。也是查询到当前文章后,直接调用 destroy 方法删掉它,返回 msg: '删除成功' 。
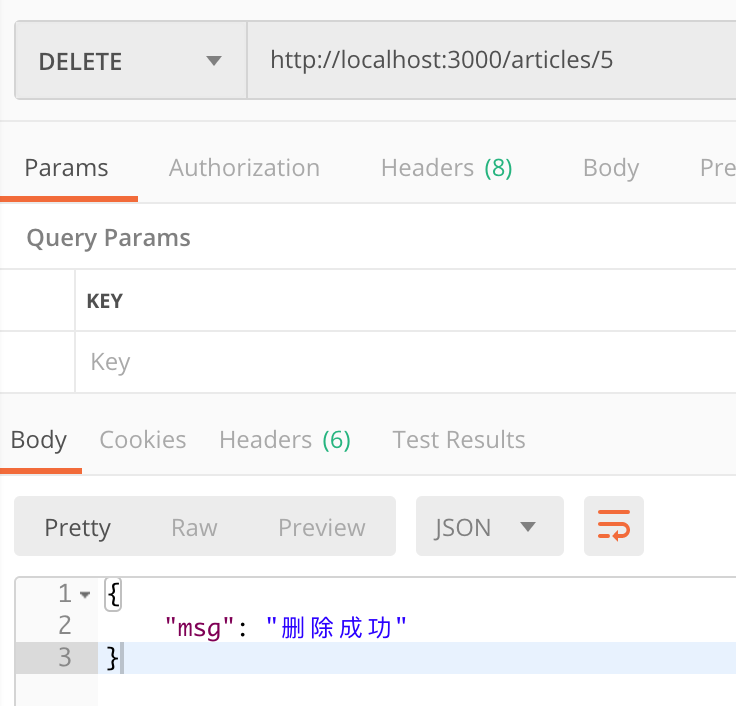
2.7.5 总结
| 路由 | 请求方式 | 含义 |
|---|---|---|
| /articles | get | 查询所有文章 |
| /articles/:id | get | 查询指定 id 的文章 |
| /articles | post | 新增文章 |
| /articles/:id | put | 编辑指定 id 的文章 |
| /articles/:id | delete | 删除指定 id 的文章 |
2.8 模糊搜索
定义一个叫做 where 的空对象,里面保存需要查询的条件。
接收title参数,where 里添加一个 like(SQL 语句语法)。前后各放了一个 %,前面有百分号,表示关键词,前面可以有其他文字。后面有百分号,就表示关键词后面,可以跟着其他文字。模型调用findAll方法。
1 | router.get('/', async function (req, res, next) { |
2 | // 搜索 |
3 | var where = {}; |
4 | |
5 | // 模糊查询标题 |
6 | var title = req.query.title; |
7 | if (title) { |
8 | where.title = { |
9 | [Op.like]: '%' + title + '%' |
10 | } |
11 | } |
12 | |
13 | var articles = await models.Article.findAll({ |
14 | order: [['id', 'DESC']], |
15 | where: where |
16 | }); |
17 | res.json({articles: articles}); |
18 | }); |
2.9 分页查询
2.9.1 分页原理
| 当前页数(currentPage) | 从哪里开始(offset) | 每页显示多少条(pageSize) |
|---|---|---|
| 1 | 0 | 10 |
| 2 | 10 | 10 |
| 3 | 20 | 10 |
由表格可知:
pageSize 参数是固定不动的,可以得出offset和currentPage的线性关系
1 | offset = (currentPage - 1) * pageSize |
2 | offset = (当前页数 - 1) * 每页条数 |
2.9.2 分页实现
当前页数(currentPage)
如果用户传了这个参数,currentPage则为用户传递的值(注:用户传递的数据都是字符串,需要使用 parseInt 方法转换);如果用户没传,则默认是 第一页。
1 | var currentPage = parseInt(req.query.currentPage) || 1; |
或
1 | var currentPage = parseInt(req.query.currentPage); |
2 | if (!currentPage) { |
3 | currentPage = 1; |
4 | } |
每页显示多少条(pageSize)
如果用户传了这个参数,pageSize则为用户传递的值;如果用户不传递参数过来,随便给它一个默认值。
1 | var pageSize = parseInt(req.query.pageSize) || 2; |
findAndCountAll、offset 与 limit
1 | var result = await models.Article.findAndCountAll({ |
2 | order:[['id', 'DESC']], |
3 | where: where, |
4 | offset: (currentPage - 1) * pageSize, |
5 | limit: pageSize |
6 | }); |
- 将
findAll改为findAndCountAll,因为findAndCountAll能返回总的记录数 - 接收值的
articles改为result,因为不仅仅有文章列表,还有记录总数 - 添加上
offset和limit参数,offset对应的值为公式得出的结果,limit的值为pageSize
响应出分页的 json
1 | return res.json(result); |
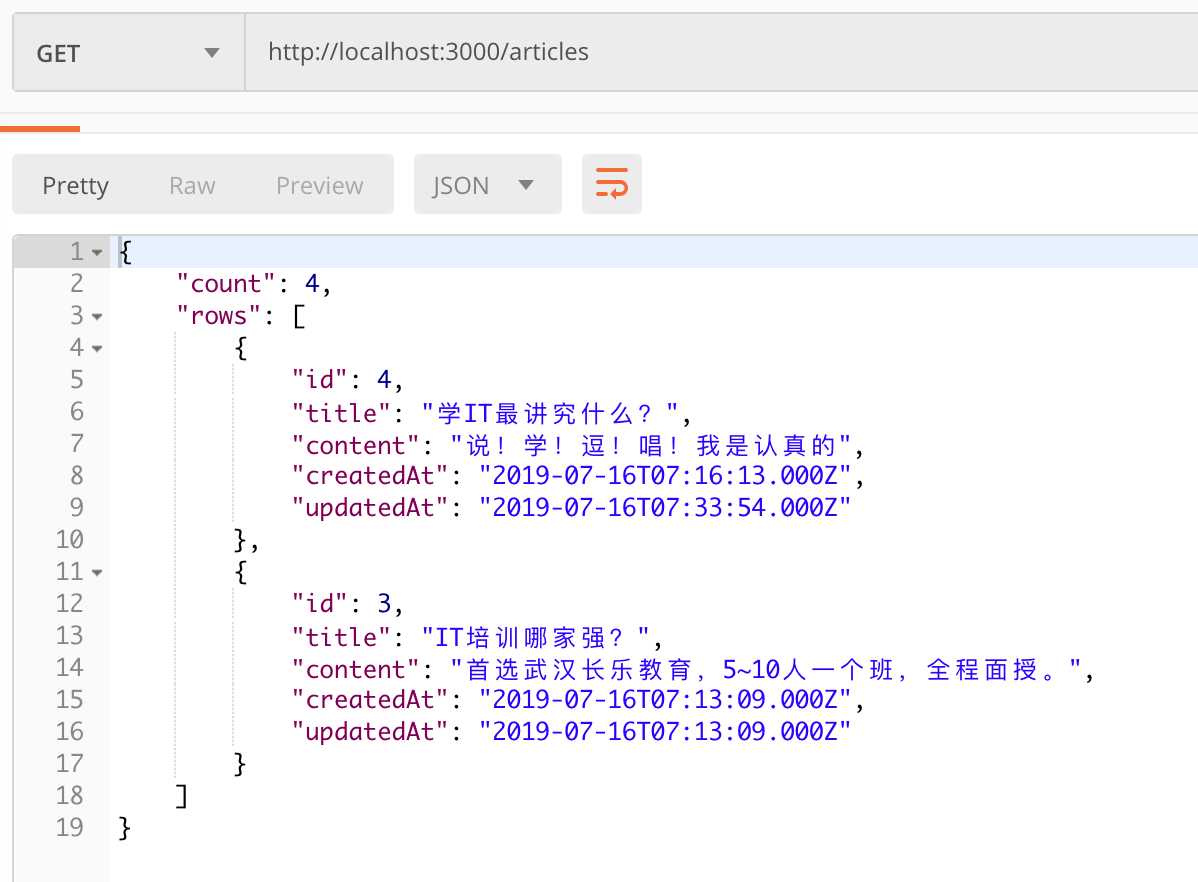
count里,保存的就是记录总数了,咱们数据库一共就是只有4条记录rows里,存的才是文章列表。
返回分页数据
1 | res.json({ |
2 | articles: result.rows, |
3 | pagination: { |
4 | currentPage: currentPage, |
5 | pageSize: pageSize, |
6 | |
7 | // 一共有多少条记录 |
8 | total: result.count |
9 | } |
10 | }); |
2.10 表的关联
2.10.1 评论模型
给文章添加上评论模块,使用关联模型,在查询文章的时候,自动查询出对应的评论。
添加评论模型代码:
1 | $ sequelize model:generate --name Comment --attributes articleId:integer,content:text |
2 | $ sequelize db:migrate |
2.10.2 种子文件
创建建种子文件
1 | $ sequelize seed:generate --name comment |
导入数据
1 | ; |
2 | |
3 | module.exports = { |
4 | up: (queryInterface, Sequelize) => { |
5 | return queryInterface.bulkInsert('Comments', [ |
6 | { |
7 | articleId: 1, |
8 | content: "这是文章1的评论", |
9 | createdAt: new Date(), |
10 | updatedAt: new Date() |
11 | }, |
12 | { |
13 | articleId: 1, |
14 | content: "这个还是文章1的评论啊", |
15 | createdAt: new Date(), |
16 | updatedAt: new Date() |
17 | }, |
18 | { |
19 | articleId: 2, |
20 | content: "这是文章2的评论", |
21 | createdAt: new Date(), |
22 | updatedAt: new Date() |
23 | } |
24 | ], {}); |
25 | }, |
26 | |
27 | down: (queryInterface, Sequelize) => { |
28 | return queryInterface.bulkDelete('Comments', null, {}); |
29 | } |
30 | }; |
刷新数据库
1 | $ sequelize db:seed --seed xxxx-comment |
2.10.3 关联
打开 models/article.js 模型
1 | Article.associate = function (models) { |
2 | models.Article.hasMany(models.Comment) |
3 | }; |
一篇文章中有很多评论
打开 models/comment.js 模型
1 | Comment.associate = function(models) { |
2 | models.Comment.belongsTo(models.Article); |
3 | }; |
每条评论都是属于一篇文章的
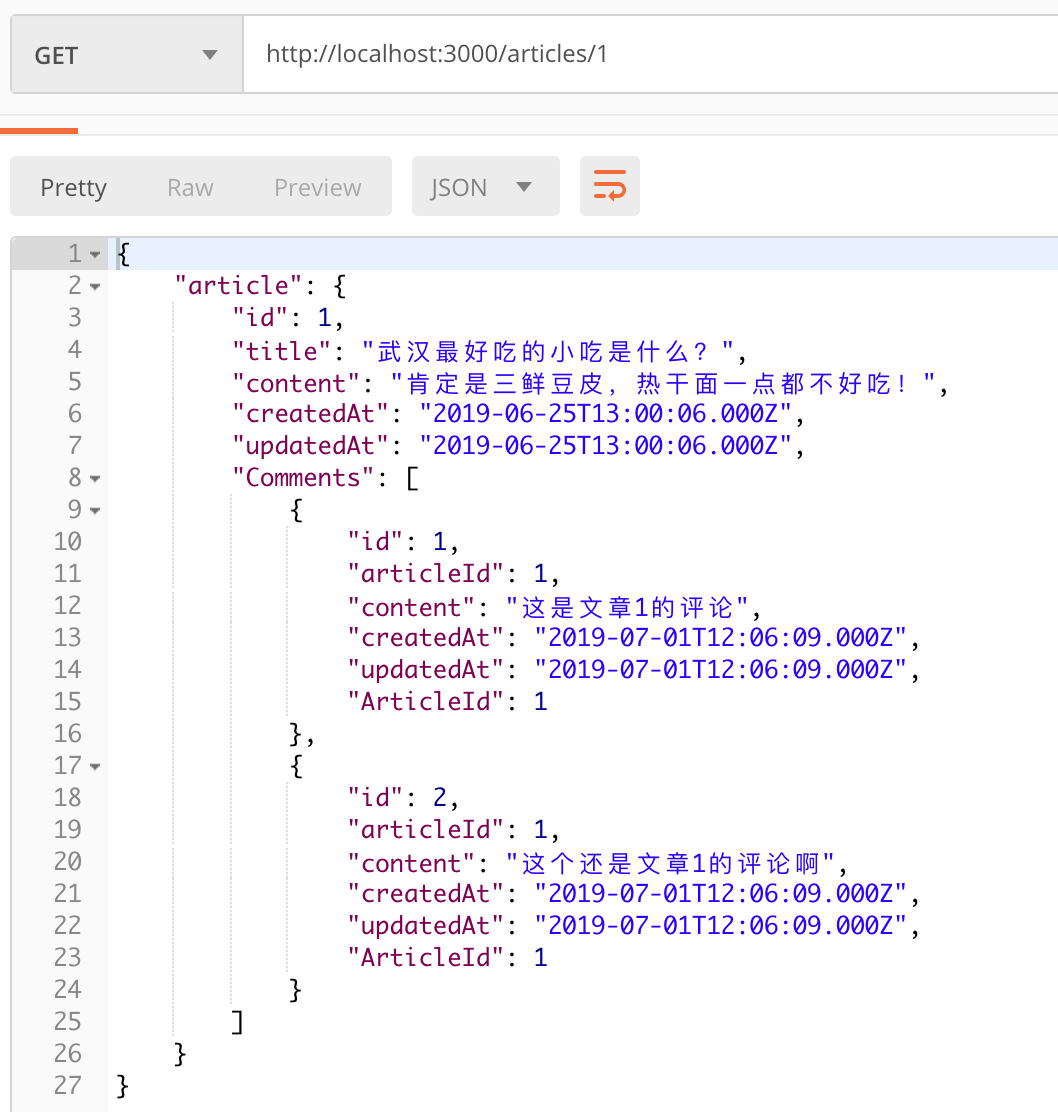
2.10.4 查询
1 | router.get('/:id', async function (req, res, next) { |
2 | var article = await models.Article.findOne({ |
3 | where: {id: req.params.id}, |
4 | include: [models.Comment], |
5 | }) |
6 | |
7 | res.json({article: article}); |
8 | }); |
加上include属性,会自动将当前文章对应的评论查出来
2.10.5 效果